完全没想到安装 mysql 会消耗掉将近一天的时间。从上午十一点,没吃饭没睡觉一直折腾到下午四点半,网上已经有了很详细的安装指导,却依旧卡在某个问题上两三个小时。文中会详细叙述。
我们可以在不同的平台以“不同的姿势”搭建 mysql 环境。
Debian 安装 MySQL
通过 官方指导手册 的章节标题我们就能感受到“姿势”的多种多样了。因为我使用的 Debian8,其官方软件库中 mysql-server-5.5,所以在此贴的链接也是 5.5 版本的。
Installing MySQL on Unix/Linux Using Generic Binaries
Installing MySQL on Linux
- Installing MySQL on Linux Using Debian Packages
- Installing MySQL on Linux Using Native Package Managers
- Installing MySQL from Source
如果你有管理员权限,很明显使用 Debian 原生的 apt-get 包管理器进行安装是最方便的。我也是敲入以下命令直接装的:
1 | apt-get update |
关于 mysql-server 和 mysql-client 的区别:
来一段引用或者 链接
打算使用 windows 上的 Navicat 访问、管理数据库的。但是在虚拟机使用 NAT 模式前提下,windows 主机无法访问安装在 Debian 虚拟机中的 mysql 数据库。从网上查找资料了解到,修改为“Bridge”模式可以让宿主机、虚拟机彼此访问,但是涉及笔记本双网卡、气象局网络环境等,还要了解虚拟机三种网络模式,不想背离初衷(上午十点我只是打算写段访问数据库的 C++11 代码)太远,所以选择放弃!以后碰到了,再回来接续这些技能。
在 Debian8Light 上卸载 mysql-server-5.5,保留了 mysql-client-5.5。
Windows7 安装 MySQL
windows 下是“姿势”多多。既然是在 windos 上安装,就使用最新的 5.7 版本了。
- Installing MySQL on Microsoft Windows Using MySQL Installer
- Installing MySQL on Microsoft Windows Using a noinstall Zip Archive
使用 MySQL Installer 安装包安装很简单,需要花费精力的是“尽可能的安装最小集,只安装那些你需要的”。对于这次的使用场景来说,我是练习写 C++ 代码用,而且已经有了 Navicat 工具。所以,我只需要安装 MySQL Server 和开发时所用的 Connector,其他的任何 GUI 工具和 Java、Python 连接器我都不需要。
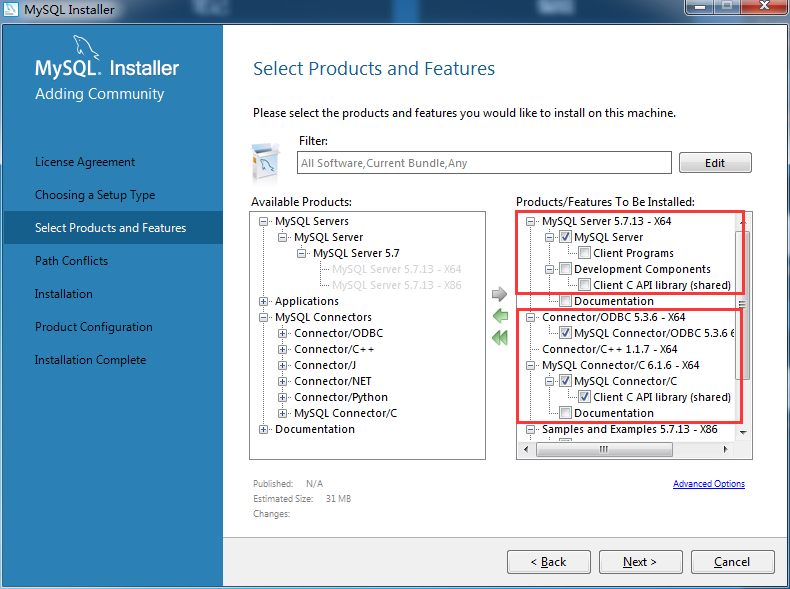
剔除那些根本就不会用到的功能花费了一些时间,除此之外,整个安装过程很顺利,装完之后连接成功直接使用。
在好奇心和心理洁癖的驱使下,我尝试搭建了 解压版 MySQL。就是在这个过程中遇到了意外,花费了两个小时才解决。
解压版本重点在于配置,根据网上的示范(5.5版本、5.6版本)搭建完毕,可是启动服务时老是失败,报错“本地计算机上的mysql服务启动后停止,……”。我当时脑袋也是不清醒,下意识地以为是配置文件的问题,或者是一台电脑安装两个实例带来的冲突。配置文件,我是把安装版的 my.ini 稍作修改直接拿过来用的,担心漏掉了某条配置没有改,造成冲突。可是校对之后仍没能解决问题;然后将安装版本卸载之后,还是出现这个错误,才反应过来直接 Google 这句错误信息。网上搜到的信息不多,但很有效。
这是一个在 5.7.7 版本之后才有的现象,新的版本需要 Initializing the Data Directory。如果英文水平不高,可以直接参考 MySQL 5.7.9 ZIP 免安装版本配置过程。
而现在 2016/7/16 18:56:44 ,我要开始码代码了。
配置文件
在 windows 上安装 msi 版本后,查看在其 /Data/ 目录下的 my.ini 配置文件。
整个配置文件分为两部分: Client Section 和 Server Section。强调 mysql 和 mysqld 是不同的两个功能,尤其是用 mysql、mysqladmin等客户端工具连接数据库时(默认)使用 Client Section 区域的 port,mysqld 启动数据库服务时监听 Server Section 区域的 port 指定的端口。仔细阅读配置文件中的注释!
权限管理
很很重要的一部分!但目前没有深入了解的必要,参考 MySQL 数据库赋予用户权限操作表 只学习以下几点:
查看权限:查看自己的权限,查看其他用户的权限
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32mysql> show grants for dba;
1141 - There is no such grant defined for user 'dba' on host '%'
mysql> show grants for dba@localhost;
+---------------------------------------------------------------------------+
| Grants for dba@localhost |
+---------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'dba'@'localhost' |
| GRANT ALL PRIVILEGES ON `testdb`.* TO 'dba'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------------+
2 rows in set
mysql> show grants for developer;
1141 - There is no such grant defined for user 'developer' on host '%'
mysql> show grants for developer@'192.168.195.%';
+-----------------------------------------------------------------------------------------------------------------------------------------------------------+
| Grants for developer@192.168.195.% |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'developer'@'192.168.195.%' |
| GRANT CREATE, DROP, REFERENCES, INDEX, ALTER, EXECUTE, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE ON `testdb`.* TO 'developer'@'192.168.195.%' |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set
mysql> show grants for common_user;
+-------------------------------------------------------------------------+
| Grants for common_user@% |
+-------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'common_user'@'%' |
| GRANT SELECT, INSERT, UPDATE, DELETE ON `testdb`.* TO 'common_user'@'%' |
+-------------------------------------------------------------------------+
2 rows in set
mysql>GRANT语句的主要用途是来给帐户授权的,但也可用来建立新帐户并同时授权。
创建 testdb 数据库,在其基础上创建 common_user developer dba 用户并授权
1
GRANT SELECT, INSERT, UPDATE, DELETE ON `testdb`.* TO 'common_user'@'%' IDENTIFIED BY 'common_user';
参考 MySQL之权限管理 了解更多的,记得去官网哦。
jack@’localhost’ 表示jack用户,@后面接限制的主机,可以是IP、IP段、域名以及%,%表示任何地方。注意:这里%有的版本不包括本地,以前碰到过给某个用户设置了%允许任何地方登录,但是在本地登录不了,这个和版本有关系,遇到这个问题再加一个localhost的用户就可以了。
WITH GRANT OPTION 这个选项表示该用户可以将自己拥有的权限授权给别人。注意:经常有人在创建操作用户的时候不指定WITH GRANT OPTION选项导致后来该用户不能使用GRANT命令创建用户或者给其它用户授权。
编写代码
MySQL Connector/C++ Developer Guide
在 C++ 中使用 MySQL 数据库,包含上述方法在内一共有 3 种:
- 使用 Connector/C++,库文件命名 (lib)mysqlcppconn.xx
- 使用 Connector/ODBC
- 使用 Connector/C,库文件命名 libmysql.xx
1 | 文件夹 PATH 列表 |