问题主要发生于将 windows 下的文本(源代码、脚本等)拷贝到 Linux 平台;反之,因为 windows 的“主动”,其开发工具、编辑器会强制转换,所以一般不会产生问题。
- gcc 编译报错让我认识到,utf8 格式的文本还分带 BOM 头,不带 BOM 头;
- vim 启动有问题认识到换行、回车到现在还在影响着跨平台;
字符集和字符编码
ansi 体系和 unicode
ansi 机构最初的 ascii 字符集,后来各国各自扩充,中国大陆和新加坡等地区使用本地编码是 GB2312 或 GBK,中国港台地区使用的本地编码是 BIG5,韩国和日本的本地编码分别是 euc-kr 和 Shift_JIS。这些从 ANSI 标准派生的字符集被习惯的统称为 ANSI 字符集,它们正式的名称应该是 MBCS(Multi-Byte Chactacter System,即多字节字符系统)。ansi 体系,字符集一般只对应一种字符编码。
再后来,为了大一统,出现了 unicode 字符集。
mbsc 和宽字节
ASCII 是 SBCS。一个字节表示的 0 用来标志 SBCS 字符串的结束。
DBCS 字符串的结束标志也是一个单字节表示的 0。
Unicode 字符串使用两个字节表示的 0 作为它的结束标志。
- 多字节(mbsc)包括 sbsc 和 dbsc 等。ascii 基本代表了 sbsc。ansi 和 mbsc 基本算同义词。
- 宽字节,unicode 基本代表了宽字节。
BOM 概念
BOM,就是 utf8-bom 中的 bom。
字节顺序标记(英语:byte-order mark,BOM)是位于码点 U+FEFF 的统一码字符的名称。统一码中,值为 U+FFFE 的码位被保证将不会被指定成一个统一码字符。Unicode 的编码点是唯一的,但表达方式(存储方式)多样。表达方式涉及 utf8,utf16 等;存储方式除了前者还涉及 字节顺序。在 UTF-16 中:
- 大尾序存储形式:数值的低有效位存储在存储地址高的位置。即
0xFE,0xFF - 小尾序存储形式:数值的低有效位存储在存储地址低的位置。即
0xFF,0xFE
UTF-8 是否应该携有 BOM 是历史问题,不做讨论。当其携有 BOM 时,按照其 编码方式,码点 U+FEFF(1111,1110,1111,1111) 会被存储为三个字节 1110(1111),10(111011),10(111111),即 0xef,0xbb,0xbf。虽然携有 BOM,但
它只用来标示一个 UTF-8 的文件,而不用来说明字节顺序
另外,在 c++11 起,新增了两个 转义字符:
\unnnn, 通用字符名(任意 Unicode 值)可能生成多个字符,表示编码点U+nnnn\Unnnnnnnn,通用字符名(任意 Unicode 值)可能生成多个字符,表示编码点U+nnnnnnnn
因为 BMP 基本多文种平面 基本包含了我们目前接触到的所有字符,所以 \U 大写的转移字符一般是用不到的。
由此,如果我们想通过 C++ 的输出流创建 utf8-bom 文件并写入 niel水 有多样的代码可选:
1 | // UTF-8 data with BOM |
error: stray ‘\357’ in program
在 linux 上某次编译时老是报错,错误信息如下:
1 | g++ -I../../include unit_test.cpp -o unit_test |
或在英文系统下:
1 | g++ -I../../include unit_test.cpp -o unit_test |
\357\273\277 (八进制)就是 EF BB BF(十六进制),这是 utf8 格式文本文件的 BOM 头。so……
产生原因:
文本文件(源代码文件 .cpp .h 等也是文本文件)的编码格式各种各样,没有明确的区分。而一些浏览文本文件的软件大多是用猜测的算法来区分这些编码,这里涉及内容很多,不多说。windows 下为了区分 UTF-8 编码格式,在以 UTF-8 编码的文本文件前写入三个字节的标志(0xef 0xbb 0xbf)来区分 UTF-8 编码的文本文件,也就是带 BOM 的 UTF-8。而 linux 下的一些编译器不识别 BOM,所以就会报错。
一般在 windows 下的文件都存成 ansi 格式,为了在 linux 下能通用,建议保存成 UTF-8 不带 BOM 编码格式,因为目前 gcc 和 g++ 不支持 UTF-8 带 BOM 编码格式。
延伸阅读:UTF8最好不要带BOM,附许多经典评论 (很值得一看)
解决方法:UTF-8编码中BOM的检测与删除 【需测试,验证…】
学习 od 命令
如何判断文件是否是使用 UTF-8 BOM 存储的?执行下面的命令:
1 | cat unit_test.cpp |hd -n 10 |
ps: hd 命令在 13x 系列服务器上不存在,在 Debian8 中有。 猜测应该是 hexdump 命令??
回车、换行是两个字符
虽然很早就意识到回车、换行的区别,在不同平台上不一致。但在新的系统、新的应用中,这个问题一般会被“抹掉”,不会再暴露出来。但在 N 年前的老机子就得注意了!
Not an editor command: ^M
将 windows 下的 vim 配置文件 _vimrc 拷贝到 mac 下,重命名为 .vimrc,本指望实现共用配置文件。但在启动 vim 时却报了以下错误:
1 | E492: Not an editor command: ^M |
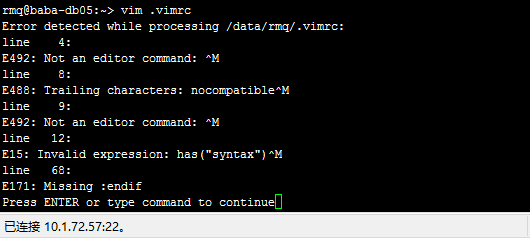
从网上搜到的相关问题的解决办法: vim 替换^M
使用 dos2unix 命令。一般的分发版本中都带有这个小工具(如果没有可以根据下面的连接去下载),使用起来很方便:$ dos2unix myfile.txt
上面的命令会去掉行尾的^M。
执行成功。推荐。
脚本莫名其妙的打印
2015年11月4日 16:19:54
先说结论:windows 下编辑的文件拿到 linux 下用,可以,但要谨慎,反之亦然。出现问题时先排除是不是回车、换行的问题。
以前接触 linux 很少,shell 更是一点都不了解。今天调试一个项目,需要运行 sh 文件。可是太蛋疼了,详述如下:
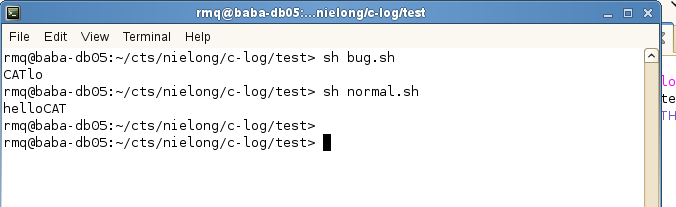
在 suse11 的环境(公司 10.0.0.57 的服务器上)下,运行 bug.sh 和 normal.sh,两者显示内容一致,如下
1 |
|
运行结果却大相径庭
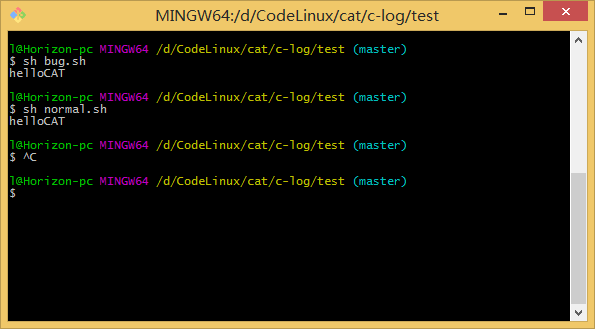
而在 windows 系统下,安装的 Git Bash Here 窗口中运行,结果一致
在 UltraCompare 中使用二进制窗口看出最终的区别,也验证了猜想
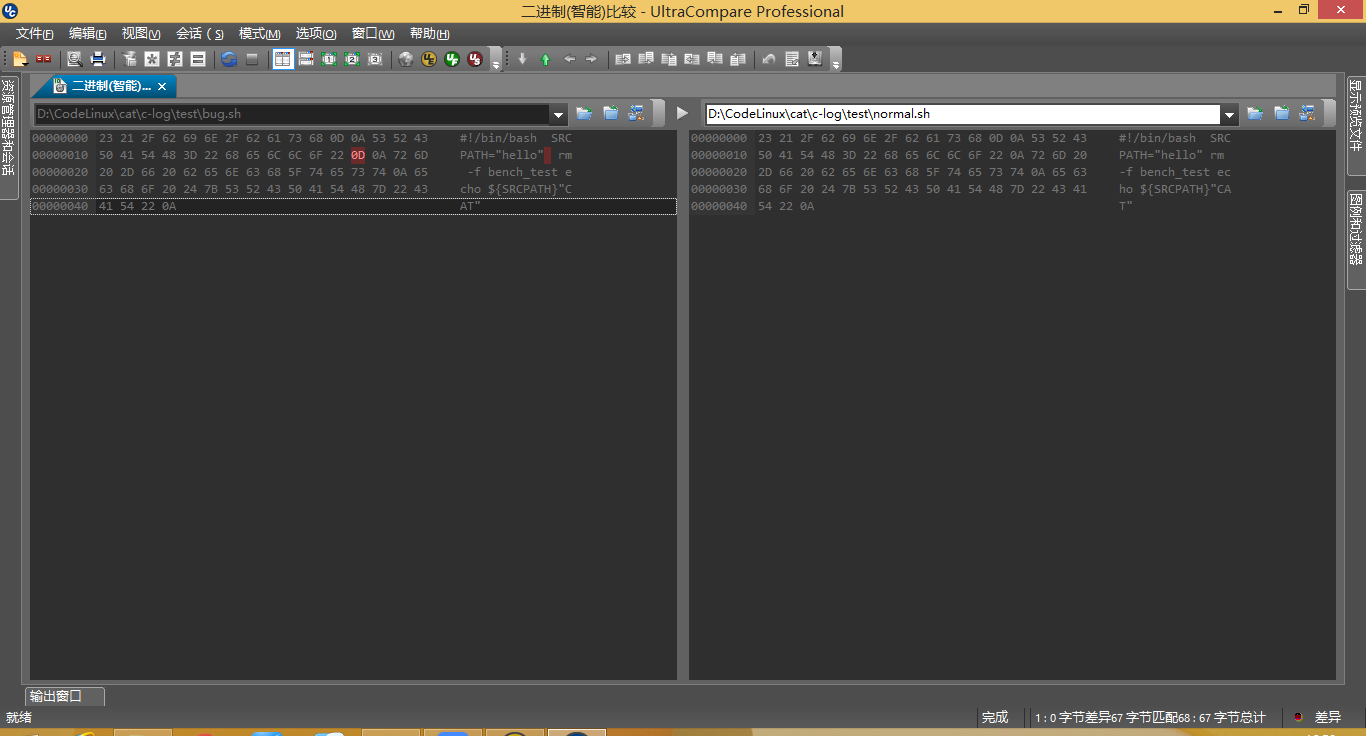
0x0d 0x0a 和 0x0a 的区别,是 windows 和 linux 的区别,当文件从 windows 拿到 linux 时,我们无法保证正在使用的 linux 版本在兼容性方面做得完美。比如 git 虽然是 linux 的背景,做的就很好;而 suse 显然在这方面尚有不足,让人在没有这方面意识、没有针对性的前提下,浪费大量时间,无从把握。
windows 系统下,回车是由两个字符构成的,0x0d 和 0x0a
| 名称 | 代码 | ASCII码 | 十六进制 | 备注 |
|---|---|---|---|---|
| 回车 | CR | \r |
0x0d | 回车的作用只是移动光标至该行的起始位置; |
| 换行 | LF | \n |
0x0a | 换行至下一行行首起始位置; |
在键盘上敲下回车键,在不同软件下获得字符大有不同。Windows 下在 txt 文件中敲下回车键,然后十六进制进制观察,你会发现获得了 2 个字符,0x0d 和 0x0a,这个大家都知道,但这不意味着,在任何情况下敲下回车键,都会获得 0x0d 和 0x0a。在 linux 下,你对一个文件,敲下回车键,你就会发现,它每次只增加一个字符 0x0a。